Week 05 - 03 - COMPSCI 712 L15 Performance Evaluation 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
这一页讲的是课程的主题和基本信息,主题是人工智能的性能评估(Performance Evaluation for AI)。
这一页讲的是课程的主题和基本信息,主题是人工智能的性能评估(Performance Evaluation for AI)。幻灯片明确了授课老师是 Daniel Wilson,课程内容基于 Prof. Jim Warren 的幻灯片设计。课程编号为 COMPSCI 712,开设时间为 2026 年第一学期。这一页主要作为课程的介绍页面,说明了课程的核心内容是如何评估人工智能系统的性能,这对于理解和优化 AI 算法的实际应用非常重要。性能评估通常涉及模型的准确性、效率、鲁棒性等多个维度,是 AI 研究和开发中的关键环节。
这一页讲的是AI有效性与性能评估。探讨AI是否比传统方法更有效,以及如何从准确性、基线比较、泛化能力和实际应用等方面评估AI的表现。
这一页讲的是AI的有效性与性能评估。首先,关于AI有效性的伦理讨论,关键问题是AI系统是否比传统方法(如依赖人类智能或较旧的自动化/半自动化方法)表现更好。这涉及到AI技术的实际价值和应用合理性。其次,评估AI性能的方法包括超越单纯的“准确性”(accuracy),还需考虑召回率(recall)、精确率(precision)等指标,以全面衡量模型的表现。此外,评估还包括将模型与基线(baseline)进行比较,即是否优于已有的标准方法;考察模型的泛化能力(generalization),即在新数据或不同环境中的表现;以及在实际应用场景中的评估(evaluation in the field),这能反映AI在真实世界中的实际效果。例如,一个AI诊断系统不仅需要在实验室中表现优秀,还需在医院实际使用中证明其可靠性和优势。这些评估方法帮助我们全面理解AI的实际价值和适用范围。
这一页讲的是二元分类问题的基础概念。主要内容包括通过特征 x 来支持决策、使用决策算法 f(x) 计算概率,以及其在机器学习中的重要性。
这一页讲的是二元分类问题的基础概念。我们试图对某个案例的重要特征进行“是”或“否”的决策,例如判断某人是否患有疾病 A。为了支持这个决策,我们需要一个或多个测量特征 x,这些特征可以是数值或向量,例如实验室测试结果等。接下来,我们使用决策算法 f(x),它根据特征 x 的测量值来计算 A 发生的概率。如果算法足够复杂,我们可以称它为人工智能(AI)。这种二元分类问题是机器学习中的经典问题设置,广泛应用于医学诊断、金融风险评估等领域。例如,在医学诊断中,特征 x 可以是患者的体检数据,算法 f(x) 可以预测患者是否患有某种疾病。这种方法的核心在于通过特征和算法的结合,提高决策的准确性和效率。
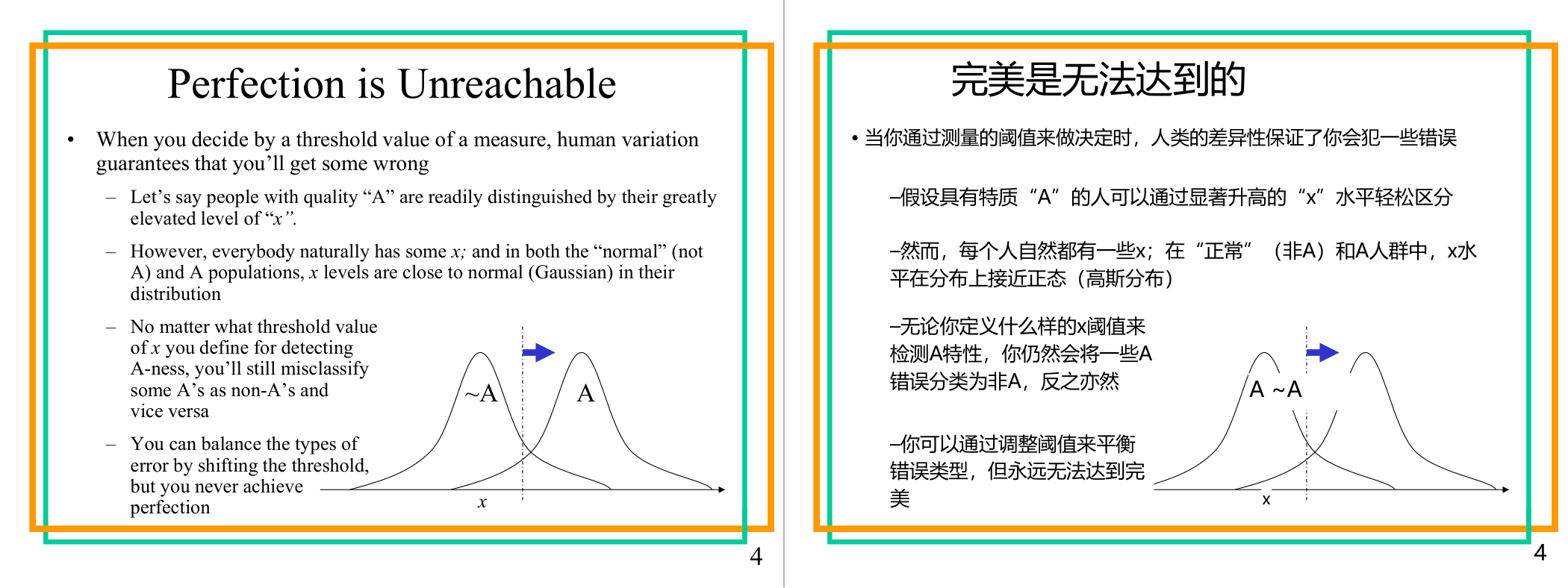
这一页讲的是分类阈值的局限性,强调人类特性导致无法实现完美分类。主要内容包括误分类的不可避免性和阈值调整的影响。
这一页讲的是分类阈值(threshold value)的局限性,即在通过某个阈值来区分两种类别时,由于人类特性和数据分布的自然变异,完美分类是无法实现的。假设我们要区分具有特性“A”的人群和普通人群(非A),可以通过某个指标“x”的水平来划分两者。虽然“A”人群的x值通常较高,但由于两类人群的x值分布都接近正态分布(Gaussian),无论如何设定阈值,总会有误分类的情况发生。例如,部分“A”的人可能被误判为非A,而部分非A的人可能被误判为A。幻灯片中的图示展示了两类分布的重叠区域,这些区域正是误分类发生的原因。通过移动阈值,可以调整两种误分类的比例(例如减少一种误分类但增加另一种),但无法完全消除误分类。这说明在实际应用中,分类决策需要权衡误差,而不是追求完美。例如,在医疗诊断中,调整阈值可能减少漏诊但增加误诊,因此需要根据具体场景优化决策。
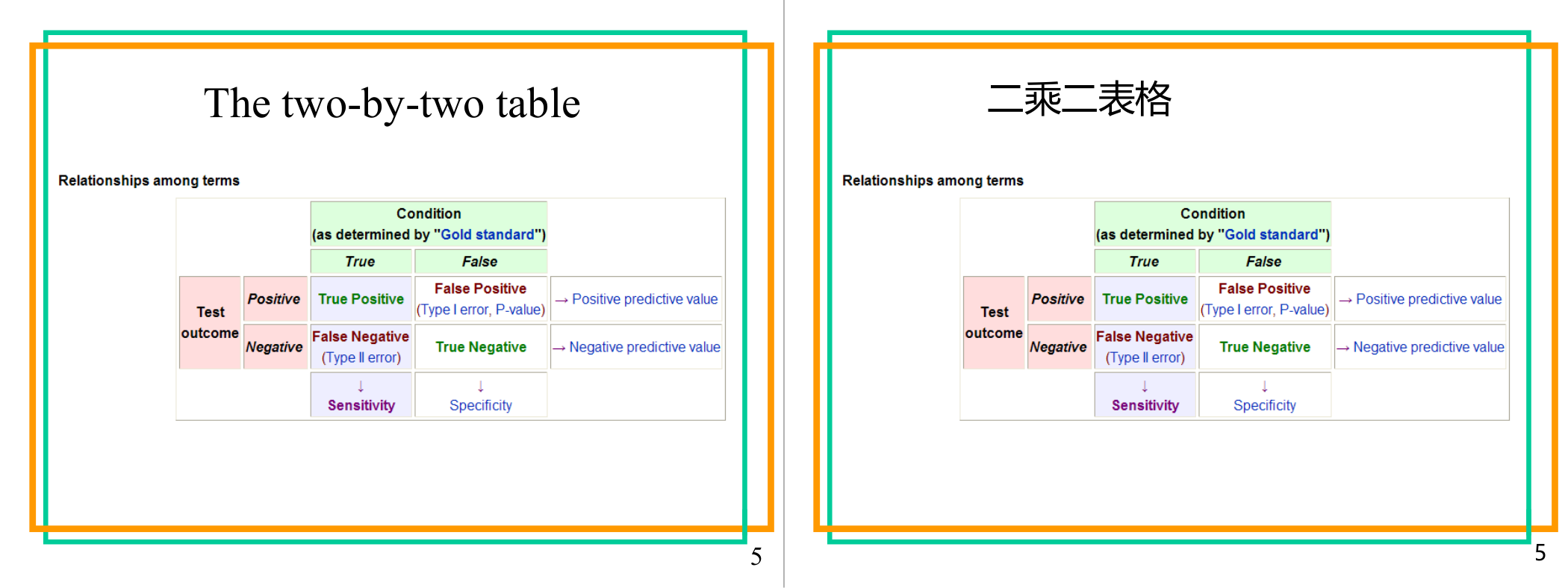
这一页讲的是二乘二表(two-by-two table),用于描述测试结果与真实情况的关系。主要概念包括敏感性(Sensitivity)、特异性(Specificity)、以及预测值。
这一页讲的是二乘二表(two-by-two table),它用来分析测试结果与真实情况的关系。表格中有两个维度:测试结果(Test outcome)分为阳性(Positive)和阴性(Negative),真实情况(Condition)依据“Gold standard”分为真实(True)和假(False)。表格的四个关键单元格分别是:真阳性(True Positive)、假阳性(False Positive)、真阴性(True Negative)和假阴性(False Negative)。敏感性(Sensitivity)表示在真实情况为真时测试能正确检测出的比例,特异性(Specificity)表示在真实情况为假时测试能正确检测出的比例。此外,假阳性与假阴性分别对应第一类错误(Type I error)和第二类错误(Type II error)。预测值分为阳性预测值(Positive predictive value)和阴性预测值(Negative predictive value),分别表示测试结果为阳性或阴性时的准确性。这张表帮助我们评估测试的可靠性和准确性,例如在医学诊断中判断某种检测方法的实际效果。
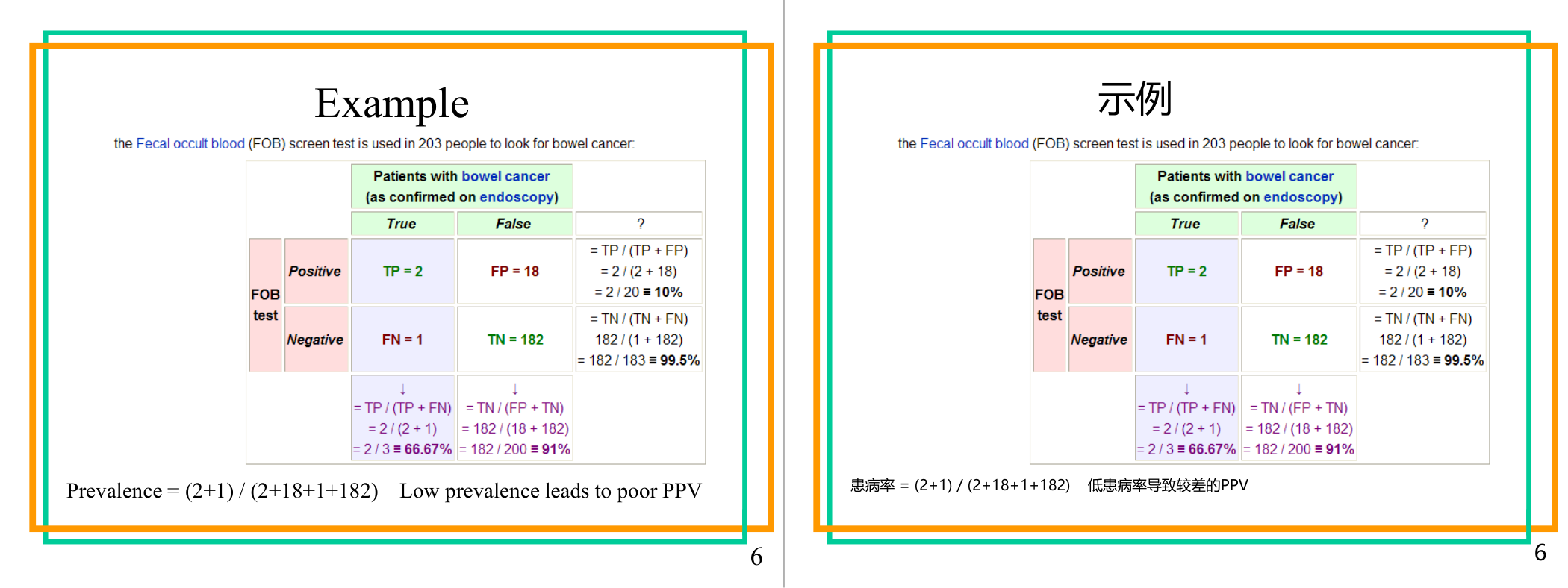
这一页讲的是粪便潜血试验(FOB test)用于筛查肠癌的效果分析。主要涉及敏感性(Sensitivity)、特异性(Specificity)和阳性预测值(PPV)。
这一页讲的是粪便潜血试验(FOB test)在筛查肠癌中的效果分析。表格展示了203名受试者的测试结果,其中通过内镜确诊肠癌的患者为3人(2名测试阳性TP,1名测试阴性FN),未患肠癌的人为200人(18名测试阳性FP,182名测试阴性TN)。敏感性(Sensitivity)计算公式为TP / (TP + FN),结果为2 / (2 + 1) = 66.67%,表示检测出患病的能力;特异性(Specificity)为TN / (TN + FP),结果为182 / (182 + 18) = 91%,表示检测出未患病的能力;阳性预测值(PPV)为TP / (TP + FP),结果为2 / (2 + 18) = 10%,显示阳性结果真正患病的概率。低患病率(Prevalence)为(2 + 1) / 203 = 1.48%,这导致PPV较低。图表强调了患病率对PPV的影响,低患病率会降低筛查试验的阳性预测值。
这一页讲的是决策工具的评价指标,包括Sensitivity、Specificity、PPV和NPV。
这一页讲的是决策工具的评价指标,主要包括四个关键概念:Sensitivity(敏感性)、Specificity(特异性)、Positive Predictive Value(PPV,阳性预测值)和Negative Predictive Value(NPV,阴性预测值)。敏感性计算公式是TP/(TP+FN),表示测试能够正确检测到实际存在情况的百分比,也叫Recall(召回率)。特异性公式是TN/(TN+FP),表示测试在实际不存在情况下正确报告为阴性的百分比。PPV公式是TP/(TP+FP),表示测试在报告为阳性时正确的概率,也称为Precision(精确率)。NPV公式是TN/(TN+FN),表示测试在报告为阴性时正确的概率。这些指标在评估分类模型或诊断工具的性能时非常重要。例如,敏感性高的工具可以减少漏检,而特异性高的工具可以减少误报。PPV和NPV则帮助理解预测结果的可靠性。
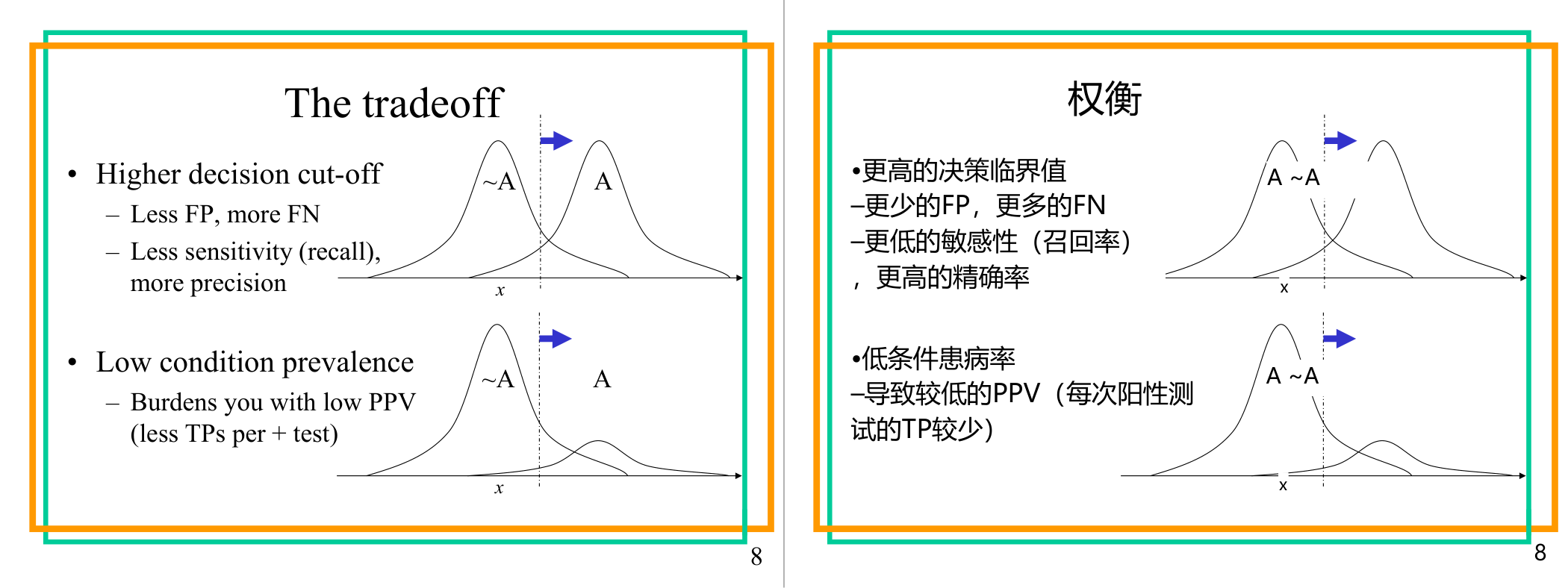
这一页讲的是决策阈值与条件流行率之间的权衡。主要讨论了高决策阈值对敏感性和精确性的影响,以及低条件流行率对预测值的负面影响。
这一页讲的是决策阈值 (decision cut-off) 和条件流行率 (condition prevalence) 的权衡问题。第一部分提到,高决策阈值会减少假阳性 (FP),但增加假阴性 (FN),从而降低敏感性 (recall),但提高精确性 (precision)。图中展示了两个分布,分别表示条件存在 (A) 和条件不存在 (~A) 的情况,决策阈值的提高导致更多数据被归类为条件不存在,减少了错误分类的假阳性,但也错过了一些真实的条件存在数据。第二部分讲低条件流行率的影响,指出它会导致预测值的正预测值 (PPV) 降低,因为测试中真实阳性 (TP) 的比例减少。图中显示了条件流行率低时,条件存在分布 (A) 的面积相对较小,进一步加剧了正预测值的下降。这些权衡在实际应用中非常重要,例如医疗诊断中需要根据具体需求调整阈值以平衡敏感性和精确性。
这一页讲的是假阳性(False Positives)问题及 PPV 与疾病流行率的关系。主要强调即使测试敏感性和特异性很高,低流行率时 PPV 仍可能很低。
这一页讲的是假阳性(False Positives)问题,特别是 PPV (Positive Predictive Value, 阳性预测值) 与疾病流行率(Prevalence)的关系。幻灯片指出,即使测试的敏感性(Sensitivity, Recall)和特异性(Specificity)都达到 95%,如果疾病在人群中的流行率很低,PPV 仍可能非常低。表格展示了不同流行率下的 PPV:当流行率为 0.1% 时,PPV 仅为 1.9%;流行率为 1% 时,PPV 提升至 16%;流行率达到 10% 和 20% 时,PPV 分别为 68% 和 83%;而流行率为 50% 时,PPV 达到 95%。这说明流行率对 PPV 的影响非常显著。为了改善结果,可以通过调整决策标准,使疾病与非疾病分布更好地分离,或者提高阈值,接受更高的假阴性(False Negative)率。举例来说,在筛查罕见疾病时,尽管测试性能高,但低流行率可能导致大量假阳性结果,因此需要优化决策策略以减少误诊。
这一页讲的是准确率(Accuracy)的定义及其局限性。准确率计算公式为 (TP+TN)/(TP+TN+FP+FN),这里的准确率是 90.6%。但由于疾病低流行率,仅靠准确率可能不适合作为筛查测试的评价指标。
这一页讲的是准确率(Accuracy)的定义及其局限性。准确率的公式是 (TP+TN)/(TP+TN+FP+FN),即正确预测的次数除以总样本数。在图中,粪便潜血测试(FOB test)用于筛查 203 名患者的结肠癌,其中真实阳性(TP)为 2,假阳性(FP)为 18,假阴性(FN)为 1,真实阴性(TN)为 182。计算得出准确率为 90.6%。然而,仅假设所有人都没有结肠癌,准确率也能达到 98.5%,这表明在疾病低流行率的情况下,准确率可能无法有效反映筛查测试的实际效果。幻灯片还指出,筛查测试通常需要成本低、覆盖面广的工具(如 FOB test),后续再使用更昂贵且侵入性的诊断手段(如结肠镜检查)进行确认。
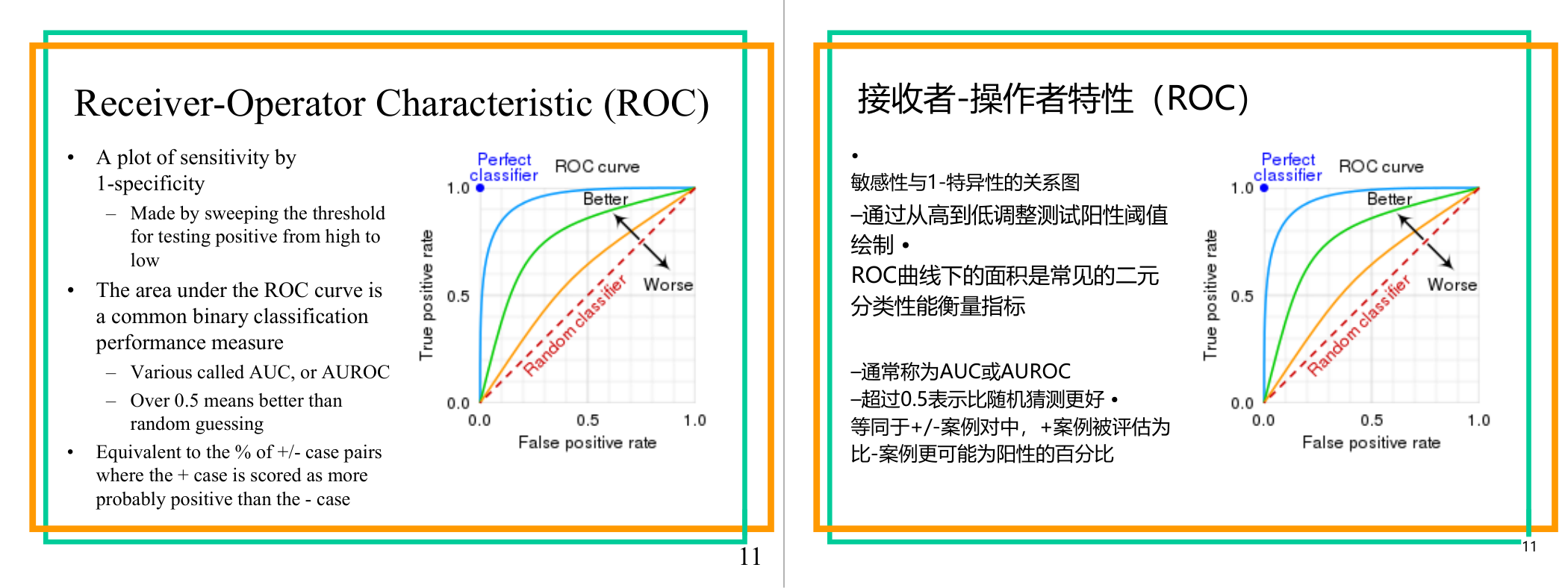
这一页讲的是 Receiver-Operator Characteristic (ROC) 曲线。ROC 曲线展示了敏感性 (Sensitivity) 与 1-特异性 (1-Specificity) 的关系,并通过改变阈值绘制。曲线下的面积 AUC 是评估分类器性能的重要指标。
这一页讲的是 Receiver-Operator Characteristic (ROC) 曲线,它是用于评估二分类模型性能的工具。ROC 曲线通过绘制敏感性 (True Positive Rate) 与 1-特异性 (False Positive Rate) 的关系来表示分类器的能力。曲线是通过逐步改变预测为正的阈值从高到低生成的。图中展示了三种分类器的表现:完美分类器 (Perfect Classifier) 的曲线最靠近左上角,表示性能最佳;随机分类器 (Random Classifier) 的曲线是对角线,表示性能最差;更好的分类器 (Better) 的曲线介于两者之间。曲线下的面积 (Area Under Curve, AUC 或 AUROC) 是一个常用的性能指标,值越接近 1,分类器性能越好;如果 AUC 超过 0.5,说明分类器优于随机猜测。AUC 的直观意义是表示正负样本对中,正样本被分类为正的概率高于负样本的百分比。例如,AUC 为 0.8 表示 80% 的正负样本对中,正样本的预测概率高于负样本。这一指标在机器学习模型评估中非常重要,可以帮助我们比较不同模型的优劣。
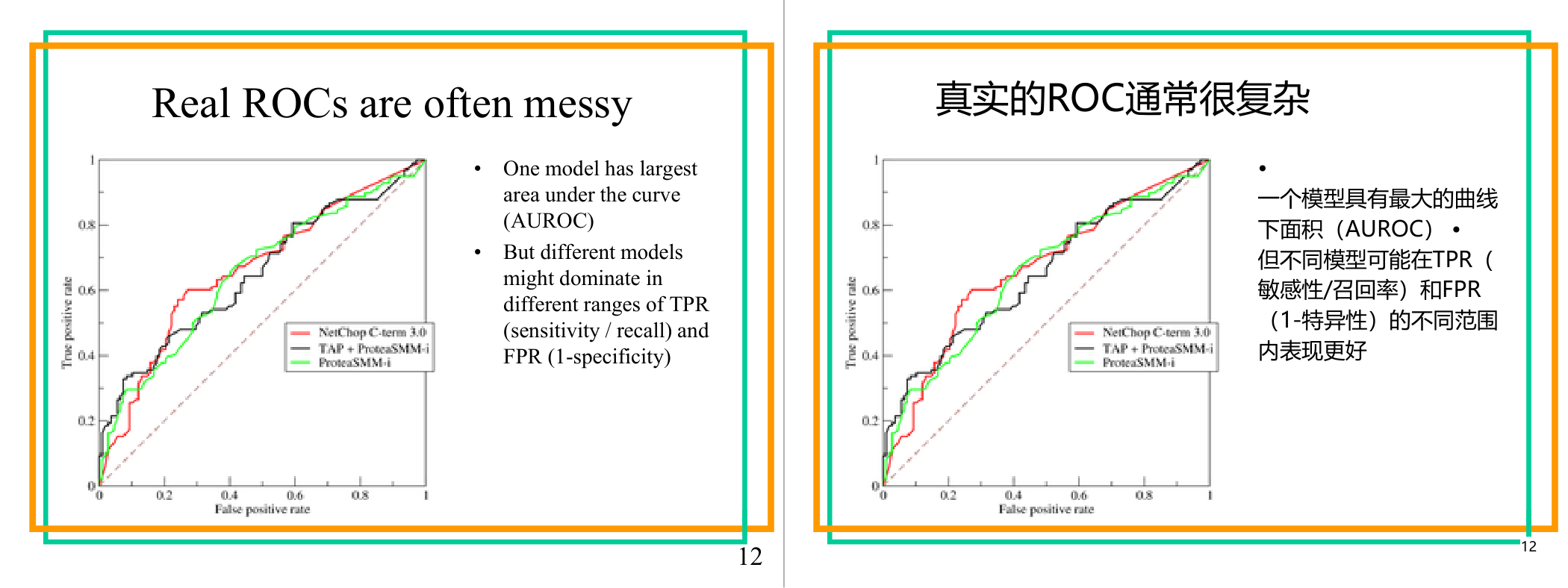
这一页讲的是真实的 ROC 曲线通常较复杂。主要讨论了 AUROC 和不同模型在 TPR 和 FPR 范围内的表现差异。
这一页讲的是真实的 ROC 曲线(Receiver Operating Characteristic Curve)通常较复杂。ROC 曲线展示了模型在不同阈值下的性能,横轴是假阳性率(False Positive Rate, FPR),纵轴是真阳性率(True Positive Rate, TPR)。图中有三条曲线,分别代表三个模型:NetChop-Cterm 3.0、TAP+ProteasSMM-i 和 ProteasSMM-i。通过观察可以发现,虽然某个模型可能具有最大的曲线下面积(Area Under the Curve, AUROC),但在不同的 TPR 和 FPR 范围内,不同模型可能表现更优。比如某模型在低 FPR 时表现较好,而另一个模型在高 TPR 时更具优势。这说明单纯依赖 AUROC 可能无法全面反映模型的实际性能。举例来说,如果一个应用场景对低假阳性率特别敏感,那么选择在这一范围内表现更好的模型可能更合适。
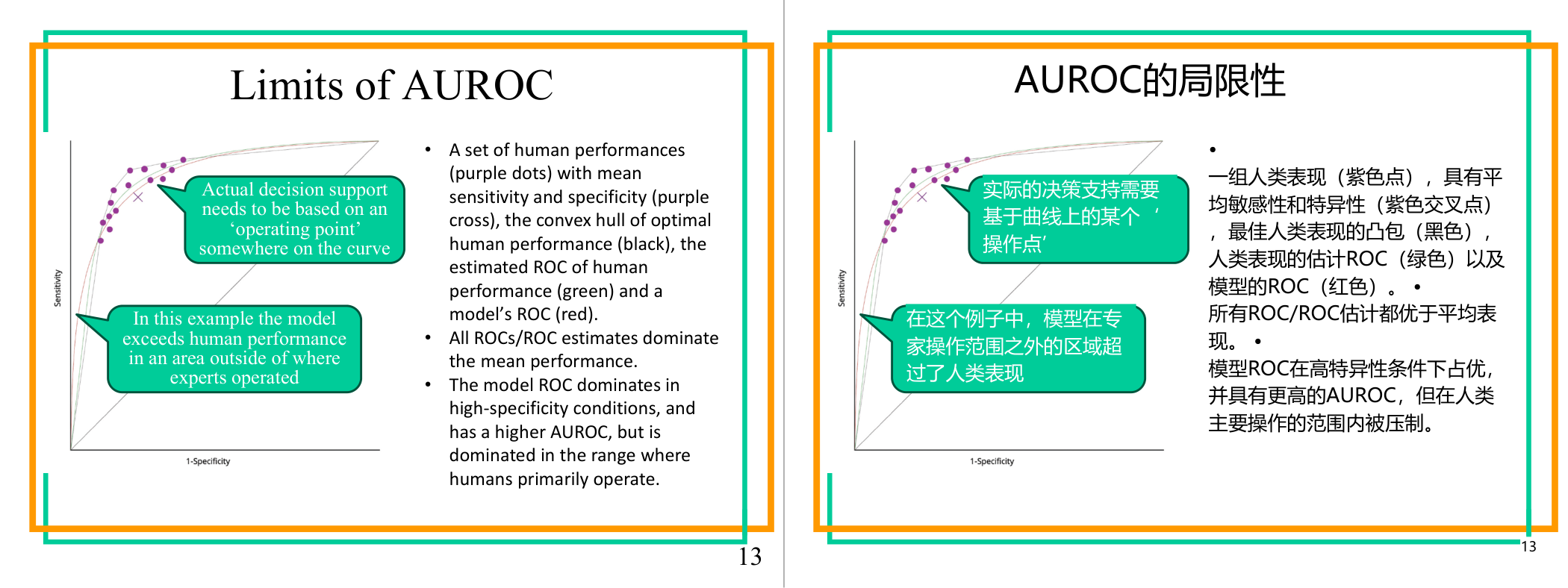
这一页讲的是 AUROC 的局限性,重点分析模型与人类表现的比较。主要包括 ROC 曲线的操作点选择和模型在某些区域超越人类表现的情况。
这一页讲的是 AUROC 的局限性,重点分析模型与人类表现的比较。图中展示了人类表现的多个点(紫色点)及其平均敏感性和特异性(紫色交叉点),还有人类表现的凸包(黑色曲线)、估算的 ROC(绿色曲线)以及模型的 ROC(红色曲线)。所有 ROC 和 ROC 估算值都优于平均表现,但模型的 ROC 在高特异性区域占优,整体 AUROC 更高。然而,在人类主要操作的区域,模型的表现被人类主导。图中的绿色框说明实际决策支持需要基于 ROC 曲线上的某个操作点,而模型在某些专家未操作的区域超越了人类表现。这表明 AUROC 虽然是一个整体性能指标,但在实际应用中需要结合具体的操作点选择来评估模型的实际价值。例如,在医疗诊断中,模型可能在某些条件下表现优异,但需要考虑实际应用场景中对敏感性和特异性的具体需求。
这一页讲的是 Precision-Recall,适用于低正例比例情况的评估方法,强调 PR 曲线面积和 F1 分数的重要性。
这一页讲的是 Precision-Recall(精确率-召回率),主要用于低正例比例(low prevalence situations)的场景。在这种情况下,传统的评估指标如 AUC(曲线下面积)和 Accuracy(准确率)可能表现不佳,因此推荐使用 PR 曲线面积和 F1 分数。PR 曲线面积表示模型在不同阈值下精确率和召回率的综合表现,能够更好地反映模型性能。F1 分数是精确率(Precision)和召回率(Recall)的调和平均值,公式为:F1 = 2 (Precision Recall) / (Precision + Recall)。它权衡了模型在预测正例时的准确性和覆盖率,尤其适用于需要平衡两者的任务。例如,在医疗诊断中,低正例比例可能意味着疾病患者较少,此时 F1 分数比准确率更能反映模型的实际效果。
这一页讲的是超越二元分类的任务,包括预测连续值和多类别分类问题的评估方法。
这一页讲的是机器学习中的两种任务类型:预测连续值和多类别分类问题。第一种情况是预测一个实数(real number)或实数向量,例如年薪或血压。这类任务通常使用均方误差(Mean Squared Error, MSE)或其平方根(Root Mean Squared Error, RMSE)作为评估指标,反映预测值与真实值之间的偏差。第二种情况是多类别分类问题,即预测属于 k > 2 的类别。这类任务可以使用准确率(accuracy)作为评估指标,但当类别数 k 较多时,准确率可能过于严格。为了全面评估分类性能,可以使用混淆矩阵(confusion matrix),它能够展示模型在各类别上的预测情况,帮助发现错误分类的模式。例如,在一个三类别问题中,混淆矩阵可以显示模型是否倾向于将某一类别误分类为另一个类别,从而指导模型改进。
这一页讲的是情感上下文检测的混淆矩阵示例。主要内容包括使用 BERT 模型分析情感分类的准确性,以及混淆矩阵中显示的分类误差。
这一页讲的是情感上下文检测的混淆矩阵示例,旨在通过对用户情感的准确识别,提升聊天机器人对话的安全性和针对性。幻灯片中提到,研究使用了 Mechanical Turk 平台上的文本数据,这些数据记录了人们描述自己感受到的情感(如 happy、sad、hopeful 等)。此外,研究使用了基于 Wikipedia 等数据预训练的 BERT 编码器进行情感分类。页面的混淆矩阵展示了模型对六种情感(faithful、terrified、excited、angry、sad、hopeful)的预测结果与实际标签的对应关系。矩阵中的数值表示模型预测结果的概率分布,主对角线上的值较高,说明模型在正确分类上的表现较好。然而,研究也指出了最大的混淆点,包括 hopeful 和 excited(21.8%)以及 sad 和 angry(13.0%)之间的分类错误。这表明模型在区分这些情感时存在一定困难。举例来说,用户描述一种“希望”的情感时,模型可能会误判为“兴奋”,这可能影响对话的准确性和后续反应的质量。
这一页讲的是数据有效性威胁,重点在训练集和测试集的划分及其重要性。提到 K 折交叉验证和时间序列数据可能出现的训练测试泄漏问题。
这一页讲的是数据有效性的威胁,强调训练集和测试集划分的重要性。如果划分不当,像神经网络(NN)这样的技术可能会过拟合。测试数据必须完全独立于训练过程,包括超参数搜索(如网络学习率的调整)。K 折交叉验证通过多次划分训练集和测试集,可以观察模型在不同数据分布下的性能变化,从而提高评估的可靠性。右侧图表展示了 K 折交叉验证的过程,每次迭代中测试集和训练集的划分方式不同。对于时间序列数据,可能会出现训练测试泄漏的问题,例如,如果训练数据中包含周一和周三的数据,可能会间接推测出周二的情况。这种泄漏在某些场景中会导致模型评估失真,比如处理新闻分类任务时(如 Reuters-21578 数据集)。
这一页讲的是研究中的其他效度威胁,包括多重比较和外部效度问题。多重比较可能导致假阳性结果,外部效度强调模型在不同场景的适用性。
这一页讲的是研究中的其他效度威胁,主要包括两部分:多重比较(Multiple comparisons)和外部效度(External validity)。多重比较指当我们尝试多种方法时,仅靠随机性可能会产生显著性结果,例如尝试20种方法时,可能会有一个方法在0.05显著性水平下表现突出。这种情况可能误导我们,认为某特征显著或某模型优于基线。为解决这一问题,可以使用Bonferroni校正,将关键p值(p_crit)除以比较次数(例如p_crit = 0.05/n-comparisons)。外部效度则关注模型在实验室外的表现。如果模型在中国人群数据上训练和测试,能否在新西兰医疗系统中表现良好?通常模型在实验室外的表现会有所下降(drop off)。这提醒我们在实际应用中需要考虑数据分布和场景差异,例如跨文化或跨系统的适用性问题。
这一页讲的是实际应用中分类器的目标与设计方法。重点包括关注实际结果而非分类器准确率、结果的定义与测量、随机对照试验(RCT)的重要性及定性数据的价值。
这一页讲的是在实际应用中,我们真正关心的是分类器是否能带来更好的实际结果(better outcomes),而不是仅仅关注分类器的准确率。结果(outcome)可以是更高的五年生存率(5-year survival rate),或者服务后两周满意度调查的更高评分。这些结果需要在特定时间通过精确的方式测量。此外,理想的研究设计是随机对照试验(RCT),它在生物医学领域被认为是一级证据(Level 1 evidence)。RCT要求真正随机地分配基线组和新方法组,并最好采用双盲设计(double blinding),以减少偏差。最后,定性数据(qualitative data)也很重要,例如用户或客户的反馈,尤其是他们的投诉,这些都能提供关键的洞察。例如,一个医疗决策支持工具不仅需要提高患者的生存率,还应关注患者对服务的满意度,这样才能全面评估工具的价值。
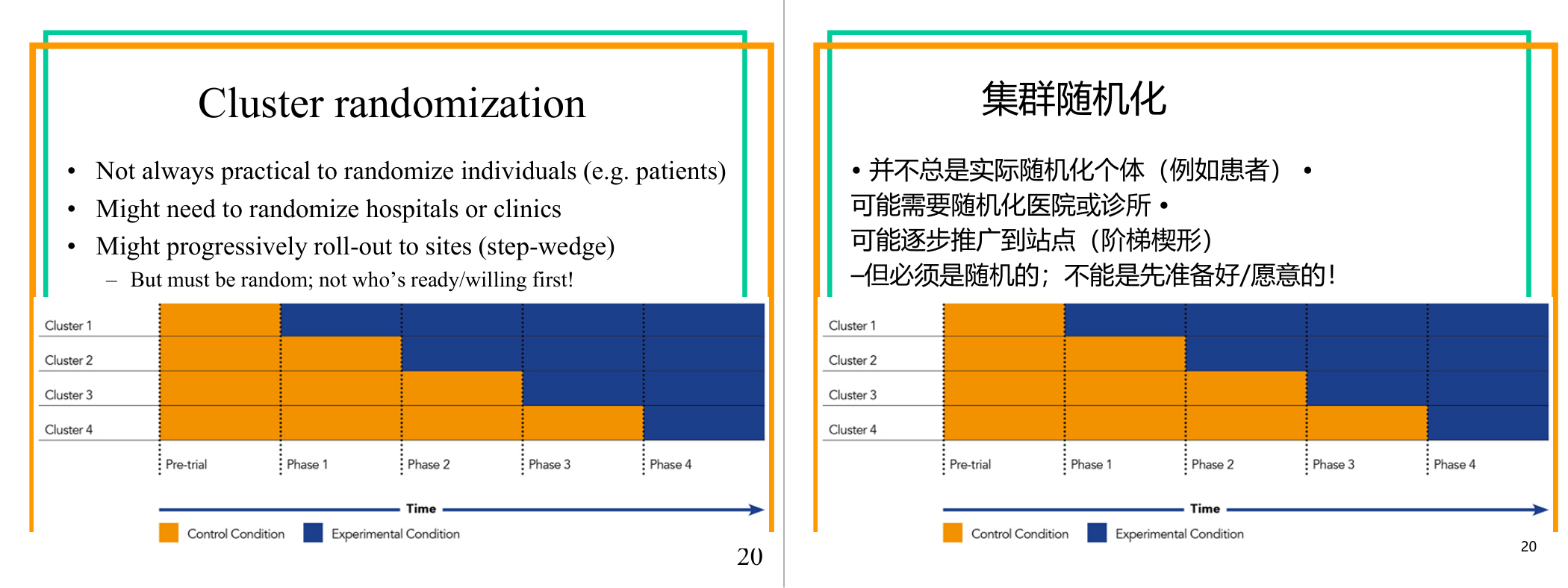
这一页讲的是Cluster Randomization(聚类随机化),包括为什么选择这种方法、如何实施逐步推广(step-wedge)以及随机化的重要性。图表展示了不同阶段的实验设计。
这一页讲的是Cluster Randomization(聚类随机化),即在某些情况下无法对个体进行随机化(例如患者),需要对更大的单位如医院或诊所进行随机化。这种方法特别适用于医疗试验或教育研究等场景。幻灯片提到一种逐步推广的设计方式(step-wedge),即实验条件逐步在不同的群体中展开,但必须确保随机化,而不能基于哪一个群体更愿意或更早准备好。图表展示了这种设计的具体实施方式:横轴表示时间,纵轴表示不同的Cluster(群体)。在Pre-trial阶段,各群体都处于Control Condition(对照条件,橙色);随着时间推进,每个群体逐步进入Experimental Condition(实验条件,蓝色)。例如,Cluster 1在Phase 1进入实验条件,而Cluster 4则在Phase 4才进入实验条件。这种设计的优点是可以逐步评估实验效果,同时保证随机化,避免偏倚。
这一页讲的是 AI 产品评价结果的可信性问题及批判性思考的重要性。主要提到厂商可能通过多种技巧夸大产品效果,以及我们需批判性看待这些结果。
这一页讲的是 AI 产品评价结果的可信性问题及批判性思考的重要性。首先,厂商为了展示其 AI 产品效果优秀,可能使用一些技巧,比如仅报告准确率(accuracy),而忽略敏感性(sensitivity)和精确度(precision);或者仅展示训练集(training set)的结果,而不提测试集(test set);即使报告测试集结果,也可能使用与实际场景不匹配的数据;此外,厂商可能避开讨论产品在实际应用中的改进效果问题,或者选择性展示某些演示站点的结果(cherry-pick)。这些做法可能导致评价结果失真或误导消费者。因此,我们作为消费者和生产者,需要对 AI 评价结果保持批判性思考,深入理解其背后的数据来源和方法。举例来说,如果一个 AI 系统声称在测试集上表现优秀,我们需要进一步询问测试数据是否真实反映了实际应用场景。
这一页讲的是参考文献,列出了两篇与医学信息学和人机性能比较相关的文献。
这一页讲的是参考文献,列出了两篇重要的学术资源。第一篇是 J.H van Bemmel 和 M.A. Musen 于 1997 年出版的《Handbook of Medical Informatics》,该书由 Springer 出版,主要涉及医学信息学领域的基础知识和应用,是研究医学信息学的经典参考书。第二篇是 M. Merry、P. Riddle 和 J. Warren 在 2021 年发表的文章《Human Versus Machine: How Do We Know Who Is Winning?》,这篇文章发表在《Methods of Information in Medicine》期刊上,讨论了通过 ROC 分析比较人在不同成本和疾病流行假设下的表现与机器的性能。这两篇文献为深入了解医学信息学以及人机性能比较提供了重要的理论和实践支持。