Week 05 - 02 - COMPSCI 712 L14 XAI 视图:双语并排 英文 中文 倍速:1x 1.5x 2x
这一页讲的是 Explainable AI(可解释人工智能)的主题,介绍课程背景和主讲人。
这一页讲的是 Explainable AI(可解释人工智能),这是 COMPSCI 712 课程的内容,时间为 2026 年第一学期。页面显示主讲人为 Daniel Wilson,内容基于 Prof. Jim Warren 的幻灯片。这一页是课程的封面,强调了可解释人工智能的重要性。Explainable AI 是人工智能领域的一个关键分支,旨在提高模型的透明度和可理解性,使得用户和开发者能够更清楚地了解模型的决策过程。这对于实际应用中建立信任、满足监管要求以及优化模型性能都非常重要。
这一页讲的是可解释人工智能(XAI)的概述,包括其技术选项和局限性,以及性能评估的重要性。
这一页讲的是可解释人工智能(Explainable AI, XAI)的概述,重点在于帮助解释AI模型的决策过程。首先回顾了昨天讨论的内容,包括解释是否必要、透明性和可靠性的问题。今天将进一步探讨XAI的技术选项及其局限性,并在后续课程中讨论性能评估(如何评估可靠性)。XAI的核心目标是通过技术手段使AI模型的决策过程更加透明和易于理解。幻灯片提到了一些具体的技术,例如LIME(Local Interpretable Model-agnostic Explanations),一种著名且灵活的“黑箱”解释技术。此外,还提到通过特征降维和使用可解释模型实现XAI的方法,同时指出在实现过程中可能面临的障碍。这些内容对于理解如何提升AI模型的透明性和用户信任度非常重要,例如在医疗诊断中,解释模型如何得出结论可以帮助医生做出更好的决策。
这一页讲的是解释性(explainability)的重要性,主要包括三个方面:解释权、审计(audit)和专业决策支持。
这一页讲的是解释性(explainability)的重要性,阐述了为什么需要关注人工智能算法的可解释性。首先是解释权(Right to an explanation),例如欧盟的《通用数据保护条例》(GDPR)规定,个人有权获得自动化决策的解释,例如信用决策和工作申请筛选。这体现了法律对透明度的要求。其次是审计(Audit),虽然我们可能不需要了解算法的具体工作原理,但我们希望知道它的决策结果及其影响。这种需求强调了对算法结果的有效理解,而不是关注其内部机制。最后是专业决策支持(Professional decision support),医生或律师等专业人士不能将责任完全转移给算法,他们需要理解算法的建议,以便对决策负责。这些内容说明了解释性不仅是法律和伦理的要求,也是实际应用中的必要条件,有助于增强信任和责任感。
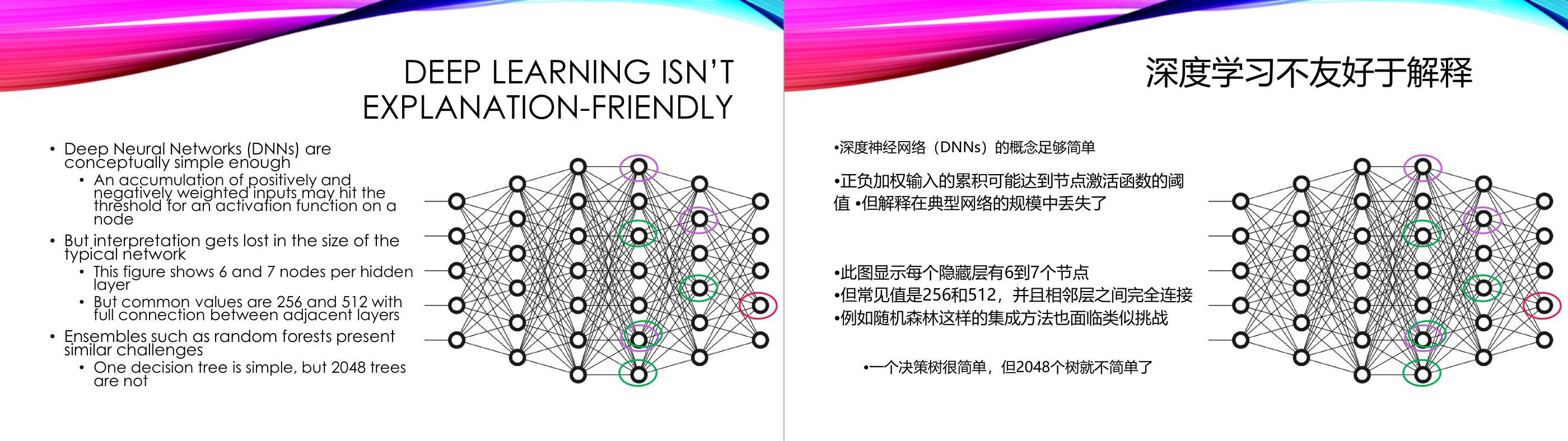
这一页讲的是深度学习模型的解释难度及其复杂性。主要提到深度神经网络(DNNs)的基本原理、解释性问题,以及与随机森林的对比。
这一页讲的是深度学习模型的解释性问题。首先,深度神经网络(Deep Neural Networks, DNNs)在概念上相对简单:它通过正负加权输入的累积,触发节点的激活函数。然而,随着网络规模的增大,模型的解释性逐渐丧失。幻灯片中的图例展示了一个典型的神经网络,其中隐藏层包含 6 和 7 个节点,但实际应用中常见的节点数可能是 256 或 512,并且每层节点之间是全连接的。这种复杂的连接使得追踪模型的决策路径变得困难。此外,幻灯片还提到随机森林(Random Forests)也面临类似的挑战:单个决策树的逻辑相对简单,但当树的数量达到 2048 时,模型的解释性同样受到影响。这说明,无论是深度学习还是集成学习模型,随着复杂性的增加,模型的可解释性都会显著下降。
这一页讲的是 LIME 方法,用于解释模型的预测结果。它适用于任何模型,包括黑箱模型,并通过生成点、加权和应用代理模型来实现解释。
这一页讲的是 LIME(Local Interpretable Model-agnostic Explanations),一种模型无关的解释方法。它可以应用于任何类型的模型,包括深度神经网络、决策树集成等黑箱模型,只需要能够输入特征值 x 并观察模型输出 y,同时了解一些输入空间 X 的性质即可。LIME 的核心是通过局部解释来揭示模型的预测机制。具体来说,它首先在特征空间 X 中生成一组点(默认生成 5000 个),这些点的分布通常基于模型训练数据的分布。然后,使用目标模型对这些随机点(即合成样本)进行预测,得到对应的输出 y。接着,根据这些合成样本与参考样本的接近程度进行加权,最后在加权后的数据集上应用一个可解释的代理模型(surrogate model),从而得出局部解释。比如,针对一个图像分类模型,LIME可以通过分析局部区域的像素变化对分类结果的影响来解释模型的决策。这种方法对于理解复杂模型的行为和提高透明度非常重要。
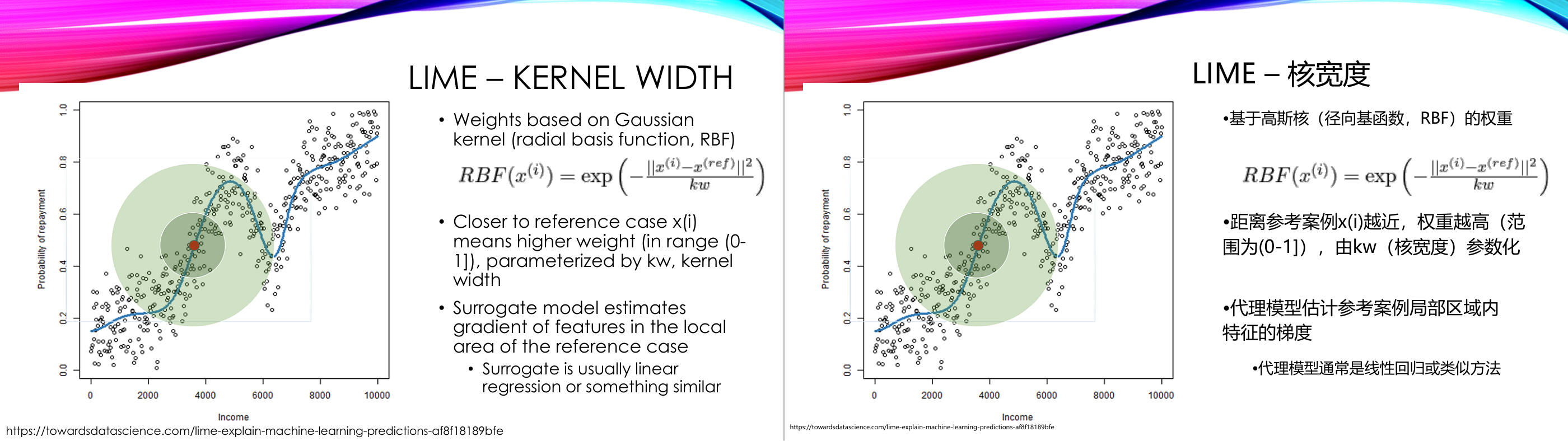
这一页讲的是 LIME 方法中的核宽度 (Kernel Width)。主要内容包括核函数的权重计算、参考点附近权重的变化,以及代理模型的作用。
这一页讲的是 LIME (Local Interpretable Model-agnostic Explanations) 方法中的核宽度 (Kernel Width)。首先,权重是通过高斯核函数 (Gaussian Kernel),即径向基函数 (Radial Basis Function, RBF) 来计算的。公式中,权重由样本点与参考点之间的距离决定,距离越近权重越高,范围在 0 到 1 之间。核宽度 (kw) 是一个参数,用于控制权重随距离变化的敏感程度。幻灯片中的图展示了一个参考点及其周围的权重分布,绿色区域表示权重较高的范围。其次,代理模型 (Surrogate Model) 用于估算参考点附近特征的梯度变化,通常采用线性回归或类似方法。这种方法的重要性在于,它能够在局部范围内解释复杂模型的行为,比如预测某人收入与还款概率之间的关系。通过调整核宽度,可以更好地平衡局部解释的范围与精度。
这一页讲的是 LIME 与线性回归的解释方法,包括线性回归公式、权重优化和 Ridge 回归的作用。
这一页讲的是 LIME(Local Interpretable Model-agnostic Explanations)与线性回归的结合及其解释方法。首先,线性回归公式为 y = β₀ + β₁x₁ + β₂x₂ + ... + βₖxₖ + ε,其中 β 表示权重或系数,ε 是误差项。权重 β 的优化目标是通过最小化样本数据的误差平方和来拟合模型。此外,Ridge 回归在优化过程中增加了一项额外的惩罚项,用于限制某些变量的过度影响,从而减少共线性问题。幻灯片还提到,LIME 的解释质量对核宽度(kernel width)敏感,而较新的算法可以自动估计这一参数。一个具体的例子是,模型可能解释为“每增加 $1000 的月收入,贷款偿还的可能性增加 20%。如果概率不足 50%,可能无法获得贷款。”这说明 LIME 能帮助用户理解模型决策背后的逻辑,同时也强调了训练数据的地理和经济背景对模型解释的影响,例如 Hamilton 和 Sydney 的生活成本差异。
这一页讲的是可解释性方法,包括线性回归和逻辑回归的特点,以及它们在概率建模和风险比计算中的应用。
这一页讲的是可解释性方法。首先,线性回归的可解释性来源于回归系数 β 的显著性,其重要性与 p(βi=0) 的显著性水平成反比。其次,逻辑回归更适合处理二分类问题,它通过公式 log(odds(y)) = log(p(y) / (1-p(y)) = β0 + β1x1 + β2x2 + ... + βkxk + ε 来建模概率,其中 log(odds) 表示对数几率。此外,逻辑回归的回归系数可以用于计算相对风险(Relative Risk)或几率比(Odds Ratio),例如,吸烟者与非吸烟者患心脏病的相对风险约为 2.0,这具有很强的解释性。虽然回归方法不如神经网络(NNs)通用,但在许多物理过程建模中仍然表现良好,尤其是在对输入变量进行变换(如平方或对数)并添加交互项(如 x1x2)时。然而,如果违反了独立性或高斯误差的假设,会影响对回归系数的解释性。
这一页讲的是特征降维(Feature Reduction),包括减少特征数量的好处、Lasso回归的自动特征选择、相关矩阵分析以及贪心前向选择方法。
这一页讲的是特征降维(Feature Reduction),主要强调减少特征数量可以让模型更容易解释和理解,尤其是选择对目标受众更有意义的特征。Lasso回归是一种自动特征选择方法,它通过惩罚系数绝对值的总和,将不重要的特征系数缩减到零,从而实现特征筛选。相关矩阵(Correlation Matrix)则可以帮助分析特征之间的相关性,如果多个特征高度相关,可以手动选择最容易解释的特征并舍弃其他特征。贪心前向选择(Greedy Forward Selection)是一种逐步添加特征的方法,先选择对模型提升效果最大的单个特征,然后逐步添加能进一步提升模型性能的特征,直到性能提升变得微不足道为止。这些方法的目标是优化模型性能,同时简化模型结构。例如,在预测房价时,可能会舍弃与房价关系较弱的特征如房间颜色,而保留房间面积等关键特征。
这一页讲的是数据缺失的填补(imputed data)及其潜在问题,包括关键特征填补和数据来源的不确定性。
这一页讲的是数据缺失填补(imputed data)对模型和决策的影响。首先,缺失值在数据处理中非常常见,但对大多数方法都是一个挑战。为了解决这一问题,可以用填补(impute)的方法,例如基于其他特征的回归模型预测缺失值,或者从该特征的分布中填入均值或随机高斯值。然而,这种填补可能会影响模型的准确性,尤其是当关键特征被填补时。其次,决策者可能会从数据代理(data broker)获取关键数据值,但他们可能不知道这些值是填补的或已过期。在大型组织中,用户可能无法追溯数据的来源,甚至不知道数据的具体构成。这些问题强调了数据质量和透明度的重要性,尤其是在依赖数据驱动决策的场景中。例如,如果一个模型依赖填补后的关键特征进行预测,而这些填补值存在偏差,可能会导致决策错误。
这一页讲的是申请房屋贷款的场景,银行拒绝贷款的原因以及解决办法。主要提到信用卡余额过高会影响贷款申请。
这一页讲的是一个模拟的房屋贷款申请对话,展示了银行在贷款审批过程中关注的因素。对话中,申请人希望获得50万美元的贷款,但银行拒绝了申请,并指出原因是申请人的信用卡余额过高。银行建议申请人减少信用卡余额后再尝试申请。这说明银行在评估贷款资格时会考虑申请人的财务状况,尤其是信用卡负债情况,因为过高的信用卡余额可能表明申请人存在较高的财务风险。这一情景强调了个人财务管理的重要性,尤其是在申请重大贷款时,保持较低的信用卡负债可以提高贷款获批的可能性。例如,如果申请人将信用卡余额减少到合理范围,银行可能会重新评估并批准贷款申请。
这一页讲的是贷款审批中的数据使用问题,重点讨论数据代理(data broker)如何影响决策,以及算法依赖数据的可靠性问题。
这一页讲的是贷款审批过程中,银行如何使用数据代理(data broker)提供的信息来评估申请人的信用情况。幻灯片通过对话展示了一个案例:申请人因被认为收入增长潜力低和教育水平低而被拒绝贷款。银行的判断依据是数据代理提供的信息,例如申请人的地址被用来推断教育水平。然而,申请人指出自己已经搬离了该地址,并且拥有高学历,但银行的算法仍然依赖数据代理的推断。这揭示了数据代理可能使用不准确或过时的信息,并且银行的算法可能过于依赖这些数据,忽略了申请人提供的真实信息。这种情况反映了算法在决策过程中可能存在的偏差和不公平性。例如,过去的居住地址可能无法准确反映申请人的当前状况,但却对贷款结果产生了决定性影响。这强调了在使用算法和数据代理时,需要更加谨慎地评估数据的质量和可靠性,以避免不公平的决策。
这一页讲的是生成式 AI 的解释问题及其局限性。主要提到 ChatGPT 的回答缺乏逻辑依据,LIME 方法难以应用于 GPT 的问题空间,以及相关研究仍在探索中。
这一页讲的是生成式 AI 的解释问题,特别是像 ChatGPT 这样的工具如何生成解释。首先,ChatGPT 可以根据请求提供解释,但这些解释仅仅是基于语言生成的可能性,并不一定反映解决方案背后的逻辑。其次,尝试使用 LIME(Local Interpretable Model-agnostic Explanations)来解释 GPT 的行为面临挑战,因为 GPT 的问题空间过于庞大,直接应用 LIME 会非常昂贵且难以解读。例如,GPT 的嵌入空间可能会产生像“答案对维度 413 和 112 非常敏感”这样的信息,但这对用户来说并不直观。此外,可以通过“假设某个词被移除”来研究模型行为,但这也只是初步探索的一部分。最后,这一领域仍是一个活跃的研究方向,未来可能会有更有效的方法来解释生成式 AI 的行为。
这一页讲的是人工智能解释性的重要性及方法,包括 LIME 算法、可解释模型和生成式 AI 的挑战。
这一页讲的是人工智能(AI)模型的解释性问题及其解决方法。首先,解释性并不是万能工具,但它可以帮助我们检查模型决策的公平性、正确性,并获得人类的认可。XAI(Explainable AI)算法,例如 LIME,可以提供深度学习模型预测背后的原因分析。通过这些算法,我们可以估算哪些因素对决策影响最大,并通过假设分析(‘what if’)研究这些因素的微小变化对结果的影响。另一种方法是使用可解释的算法,例如线性回归,或者减少决策特征的数量,这虽然可能牺牲一些性能,但能显著提升对决策的理解。此外,生成式 AI 算法的解释尤其困难,这是一个活跃的研究领域。这些内容强调了解释性在 AI 应用中的重要性,以及如何在性能和解释性之间找到平衡。
这一页讲的是参考文献,提到了一篇关于机器学习模型解释性的论文。
这一页讲的是参考文献,引用了 Ribeiro 等人在 2016 年发表的一篇论文,该论文的标题是《Model-agnostic interpretability of machine learning》,发表在 arXiv 上,编号为 arXiv:1606.05386。这篇论文讨论了机器学习模型的解释性问题,重点是如何在模型无关的情况下实现对复杂模型的解释。这对机器学习领域非常重要,因为许多模型(如深度学习)虽然性能优越,但缺乏可解释性。论文提出的方法可以帮助研究者和实践者理解模型的决策逻辑,从而增强模型的透明度和可信度。